

AIチャットボットや AIエージェント開発 が急速に進む中、多くの企業が課題として抱えているのが、hallucination(AIが事実に基づかない情報を生成する現象)と、社内データを外部サービスへ送信することによるセキュリティリスクです。特に、マニュアル・社内ナレッジ・顧客情報などの機密データを扱う企業では、「回答精度」と「データ保護」を両立できるAI基盤の構築が重要視されています。
こうした課題を解決する方法として注目されているのが、RAG(Retrieval-Augmented Generation)です。RAGは、外部データベースや社内ドキュメントを検索し、その情報をもとにAIが回答を生成する仕組みであり、生成AIの精度向上や安全な社内活用を実現できます。
さらに近年では、ノーコード/ローコードでAIワークフローを構築できる n8n を活用し、RAGシステムやAIエージェントを柔軟に開発する企業も増えています。n8nを活用することで、社内AIチャットボット、ナレッジ検索、自動化ワークフローなどを比較的低コストかつスピーディに実装できる点が大きな特徴です。
本記事では、AIエージェント開発にも活用される n8n RAG の仕組みやユースケース、AI Agentとの違いを分かりやすく解説します。さらに、ローカル環境で動作するRAGチャットボットの構築方法や、企業導入時のポイントについても詳しく紹介します。
n8n RAGの概要
n8n とは?
n8n は、オープンソースの workflow automation プラットフォームであり、ノードをドラッグ&ドロップするだけで柔軟な自動化フローを構築できます。一般的な no-code ツールと比較してカスタマイズ性が高く、API連携、データベース操作、コード実行、さらには AIエージェント開発 に必要なワークフロー構築まで対応している点が特徴です。
近年では、生成AIやLLMを業務に導入する企業が増える中で、n8n は AIワークフロー自動化 や RAGシステム構築 を実現できる基盤として注目されています。
特に以下のようなニーズを持つ企業で活用が進んでいます。
- 社内業務の自動化
- 手作業オペレーションの削減
- 複数サービス間のデータ連携
- 既存システムを活かしたAI導入
- AIチャットボットやAIエージェント開発
さらに n8n は、AI が外部ツールやAPIを呼び出してアクションを実行する「Agent + Tool」型アーキテクチャにも対応しており、AIエージェント開発プラットフォームとしても高い柔軟性を持っています。 ツールを呼び出し、実際のアクションを実行する仕組み)を実現する理想的な基盤となっています。
>>>関連記事:
RAG とは?
大規模言語モデル(LLM:Large Language Models)は、自然言語を理解・生成するために設計された巨大な機械学習モデルで、数十億〜数百億規模のパラメータを持ち、大量のテキストデータ(ウェブ全体、書籍など)を学習して構築されています。
検索拡張生成(Retrieval-Augmented Generation・RAG)とは、従来型の情報検索システム(データベースなど)が持つ「必要な情報を取り出す能力」と、大規模言語モデル(LLM)が持つ「高度な理解・文章生成能力」を組み合わせたAIアプローチです。
この仕組みによって、AIは外部知識を参照しながら回答を作成できるため、特定の目的に沿った、より正確で信頼性の高いテキストを生成することが可能になります。結果として、ユーザーは質の高い情報を効率的に得られ、課題解決や意思決定の質を向上させることができます。
>>>関連記事:
n8nでRAGワークフローとは?
まずは、「vector store」という概念について理解する必要があります。
vector storeとは、高次元ベクトルを保存・検索するために設計された特殊なデータベースです。これらのベクトルは、テキスト、画像、その他のデータを数値化した表現です。ドキュメントをアップロードすると、vector store は内容を複数の chunk に分割し、それぞれを embedding model を使用してベクトルへ変換します。
このベクトルに対して similarity search を行うことで、キーワード一致ではなく意味的な類似性に基づいて結果を取得できます。これにより、vector store は大規模な知識を検索・活用する必要がある RAG やその他の AI システムにとって、非常に強力な基盤となっています。
vector store は、n8n における RAG ワークフローの「メモリ」と考えることができます。
n8n におけるRAGワークフローとは、n8n上で「データの取得 → 埋め込み生成 → ベクターストア検索 → LLMによる回答生成」という一連の処理を自動化したワークフローを指します。
企業内のPDF、ドキュメント、Notion、データベースなどの情報を取り込み、それらをベクター化して保存し、ユーザーの質問に応じて関連情報を検索した上で、LLM が最適な回答を生成する仕組みを n8n のノーコード構成で実現したものです。
n8n RAGとn8n AI Agentの比較
n8n RAG と n8n AI Agentはどちらも LLM を利用しますが、核心となる機能や目的はまったく異なります。
主な目的
n8n RAG
→ LLM が企業データに基づいて回答できるようにする
→ 検索 + 正確な回答 に特化
利用シーン:
- ドキュメント参照チャットボット
- 社内ドキュメントの Q&A
- FAQ ベースのサポート対応
- SOP / Manual に基づく技術サポート
n8n AI Agent
→ LLM を、ワークフロー・API・ツール を呼び出せる 行動可能な Agent に変える
利用シーン:
- タスクを実行する Agent(run ワークフロー、メール送信、API コール…)
- ジョブを監視し自動実行する AI Operator
- Slack / CRM / GitHub など複数のツールを扱う AI Assistant
- 他ワークフローを判断して調整・実行
仕組み
n8n RAG
4 ステップの pipeline で構成されており、情報のクエリにのみ特化する。
Ingest → Embed → Vector Store → Retrieval → Answer
n8n AI Agent
Agent は以下を実施:
- タスクの分析
- 使用すべきツールの選択
- 別ワークフローの呼び出し
- 行動の反復(multi-step reasoning)
- 目標達成時に停止を判断
→ 回答だけでなく、実際に操作できる。
入力 ・ 出力
n8n RAG
Input: 質問 + ベクトル化されたデータ
Output: 企業データに基づいた正確な回答
→ 「回答のみ」。行動はしない。
n8n AI Agent
Input: ゴールやオープンなタスク
Output: 複数アクションを含む場合も:
- ワークフロー実行
- メッセージ送信
- API fetch
- database 更新
- ファイル生成・レポート作成
- 他タスクのオーケストレーション
→ 意思決定して実際に動く。
どちらを使うべき?
n8n RAG を使うケース
- 社内ドキュメントに基づく正確な知識が必要
- hallucination(AI が元データに存在しない情報を生成したり、誤った内容を作り出してしまう現象)を抑えたい
- 静的データを扱う場合
→ 重視するもの:知識・正確性の高い回答
n8n AI Agent を使うケース
- AI に一連のタスクを自動実行させたい
- AI が CRM・Slack・Notion・GitHub などと直接やり取りする必要がある
- 状況に応じて動的にワークフローを動かしたい
- タスクが毎回固定ではない
- AI に適切なツールを選ばせたい
→ 重視するもの:タスク実行・自動化・意思決定
| n8n RAG | n8n AI Agent | |
|---|---|---|
| 目的 | データに基づいて回答する | 複数ステップのタスクを実行する |
| 能力 | 検索、回答 | API 呼び出し、ワークフロー実行、意思決定 |
| データ | vector DBからのコンテクスト | 制限なし |
| Output | 回答 | アクション + 結果 |
| 人間らしさ | 知識の記憶 | 行動する知能 |
| 利用シーン | Q&A 情報参照 | 複雑な自動化 オーケストレーション |
これほど大きく異なる n8n RAG と n8n AI Agent ですが、果たして両者は連携できるのでしょうか。それとも、完全に独立した形でしか動作しないのでしょうか。次で詳しく見ていきます。
Agentic RAG
1.Agentic RAGとは?
Agentic RAG は、自律的な Agent を導入することで、動的な意思決定やワークフロー最適化を可能にし、従来のモデルに対してパラダイムシフトをもたらす概念です。
このモデルは「retrieval + generation」というおなじみの構造を保持しつつ、Agent の自律性を拡張することで、全体の処理をより賢く、最適化されたものにします。
従来の RAG が固定的なプロセスで動作するのに対し、Agentic RAG は複数のループを繰り返し、取得した情報を再評価しながら、複雑・多分野・リアルタイムに変化する質問にも柔軟に対応できます。
2. 従来のRAGシステムの課題と限界
| Contextual Integration | RAG が正しい情報を取得できたとしても、その情報を自然で一貫性のある回答へと統合するのは簡単ではありません。 固定的な retrieval プロセスと、深い文脈理解の不足により、回答が断片的になったり、つながりが弱かったり、内容が曖昧になることがよくあります。 |
| Multi-Step Reasoning | 多くの現実的な質問は、複数ステップの推論を必要とします。つまり「情報を取得 → 分析 → 追加取得」という流れです。 しかし従来のRAGは、中間結果やユーザーからの追加指示に基づいて retrieval を更新することが苦手なため、回答が不十分になったり、一貫性を欠くことが発生します。 |
| ScalabilityとLatencyの課題 | 外部データが増えるほど、大規模 dataset の querying・ranking に時間がかかり、拡張性が発生します。その結果、リアルタイム応答が必要なシステムでは処理速度が低下し、パフォーマンスに影響します。 |
3. Agentic RAGの特徴
Agentic RAGの主な特徴は以下のとおりです:
- Autonomous Decision-Making(自律的な意思決定):クエリの複雑さに応じて、Agent が自動的に最適な retrieval 戦略を評価・選択します。
- Iterative Refinement(反復的な洗練):フィードバックループを取り入れ、retrieval の精度や回答の関連性を継続的に向上させます。
- Workflow Optimization(ワークフロー最適化):タスクを動的にオーケストレーションし、リアルタイムアプリケーションでも効率的な処理を実現します。
Agentic RAG は、従来の「静的で一方向的な RAG」から一歩進み、思考・判断・最適化を繰り返す 「能動的なRAG」へと進化したアプローチです。
自律的なエージェントによる反復的な推論、動的なコンテキスト更新、最適な retrieval 戦略の選択により、複雑な質問やリアルタイムに変化する状況に対しても高い柔軟性と正確性を維持できます。
言い換えると、Agentic RAG は「より多くの情報を取りに行く RAG」ではなく、「状況を理解しながらより賢く動く RAG」であり、知識活用の高度化や業務プロセスの自動化において、今後の標準となるパラダイムシフトといえるでしょう。
n8nで RAG チャットボットを構築する方法(ステップ別ガイド)
n8n を活用することで、RAG の概念を実際のローカルAIチャットボットとして構築できます。
PDF ドキュメントを ingest し、Ollama で Embedding を生成、Qdrant に保存したうえで、社内データにもとづいて回答を生成するインタラクティブなチャットシステムを実装することが可能です。
このようなエンドツーエンド構成を通じて、n8n がどのようにして、プライベートかつカスタマイズ可能な RAGチャットボット や AIエージェント開発 を実現できるのかを理解できます。
特に、Ollama や Qdrant を組み合わせることで、データを外部に送信しないローカルLLM環境を構築できるため、社内ナレッジ検索、FAQ、マニュアル検索など、企業向けAIチャットボットとして幅広いユースケースに対応できます。
データの取り込み(Ingestion)
PDF やドキュメントファイルを n8n に読み込み、RAG に使用する元データを準備します。
ローカル環境では、Read Binary File ノードを使ってローカルファイルを取り込み、テキスト抽出ノードを利用して文書内容をプレーンテキストに変換します。
このステップでは「後で分割しやすいテキストの状態」に整えることが重要です。
-2-png.webp)
コンテンツの分割(Chunking)
抽出したテキストを RAG が扱いやすいサイズに「チャンク分割」します。
一般的には 300〜500 tokens 程度の長さに区切り、文章構造を保ちながら重複(overlap)を持たせることで、検索精度を高めることができます。
n8n の Function ノードや公式の Document Processing ノードを使って柔軟に分割できます。
-png.webp)
埋め込み生成(Embedding Generation)
分割したチャンクごとに Embedding を生成し、ベクトル表現へ変換します。
ローカル chatbot では Ollama Embeddings を利用するケースが多く、API キー不要でローカル推論が可能です。
このステップで作られたベクトルは後で Vector Store に登録され、クエリの検索に利用されます。
-png.webp)
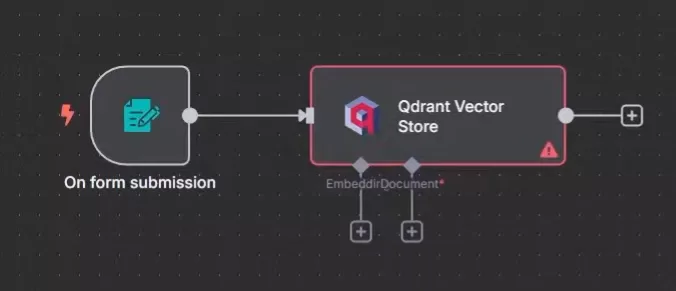
ベクトルストアへの保存(Vector Store Indexing)
生成した Embeddings を Qdrant に格納します。
Qdrant は、高速なベクトル検索に特化した Vector Database であり、多くのRAGシステム構築やAIエージェント開発で利用されています。
n8n では、Qdrant – Upsert ノードを使用して、以下の情報を保存できます。
- ベクトル(Embedding)
- 元テキストチャンク
- メタデータ(ページ番号、ファイル名など)
この Vector Store が、RAG における「知識ベース」として機能します。
クエリ受付と埋め込み生成(User Query → Embedding)
ユーザーの質問を Chat Trigger または UI ノードで受け取り、その質問文にも Embedding を生成します。
これにより、質問自体がベクトル化され、Vector Store に対して「意味に基づく検索(Semantic Search)」が実行できる状態になります。
ベクトルストア検索(Semantic Retrieval)
質問のベクトルを Qdrant に送信し、類似度が最も高いチャンク(Top-K) を取得します。
このステップによって、モデルは「回答に使うべき関連情報」を受け取ることができます。
精度を左右する重要工程で、Top-K の設定(例:3〜5)が回答品質に影響します。
-1-png.webp)
LLM を使った回答生成(LLM Generation)
取得した関連チャンクをコンテキストとして LLM(Ollama のモデルなど)に渡し、回答を生成します。
プロンプトには通常、以下の 2 種類が含まれます:
- System Prompt:
「提供されたコンテキストの内容だけに基づいて回答し、推測で答えないこと」 - User Prompt:
ユーザーの質問内容
これにより、LLM が hallucination を起こさず、取得したデータに沿った回答を生成できます。
-png.webp)
Chat UI への応答返却(Final Response)
最終的な回答を Chat UI に返却し、ユーザーとの会話として表示します。
Template の UI はマルチターン会話に対応しており、ユーザーは通常のチャットのように、何度も質問を続けられます。
-png.webp)
この RAG チャットボットのワークフローについては、n8n.io でさらに詳しく確認できます。
PDF の取り込みから埋め込み生成、ベクトル検索、そして LLM による最終回答まで、RAG のパイプライン全体を コード不要のワークフロー として組み上げられるのが n8n の大きな強みです。
特に、Ollama や Qdrant と組み合わせることで、データを外部に送らず 100% ローカルで完結する安全なチャットボット を実現できます。これは、機密文書や社内ナレッジを扱う多くの企業ユースケースにおいて大きなメリットとなるでしょう。
このエンドツーエンドの例をベースに、扱うドキュメントの種類やデータソース、使用する LLM を自由に変更しながら、ニーズに合わせてカスタマイズすることも可能です。
>>>関連記事:
まとめ
n8n RAGワークフローは、企業が AI を安全かつ柔軟に導入するための強力なアプローチです。社内データを最大限に活用しつつ、セキュリティを確保し、hallucination の発生も大幅に抑えることができます。
RAG の基礎となる Ingest → Embed → Vector Store → Retrieval → Answer という流れを、
すべてノーコードで構築できる点は、他ツールにはない n8n の大きな優位性といえます。
さらに、n8n では RAG だけでなく、AI Agent や Agentic RAG といった次世代の AI ワークフローも構築できるため、「正確な回答を返す仕組み」から「自律的に行動できる AI システム」 まで、必要に応じて段階的に拡張することが可能です。
今後は、取り扱うデータソースの拡張や、Agentic RAG を活用した高度な推論・動的な情報取得など、より高度な AI ワークフローへと発展させることも可能です。n8n の柔軟なアーキテクチャを活かし、自社の業務課題やナレッジ基盤に合わせた「最適な AI システム」をぜひ構築してみてください。
Relipa は、日本市場において長年にわたり、ソフトウェア開発・テクノロジーコンサルティング・デジタルトランスフォーメーション(DX)・AI ソリューションを提供してきた実績を持つ企業です。
Relipaのエンジニアチームは、n8nの運用だけでなく、システムアーキテクチャ、データ基盤、AI モデル運用の専門知識にも精通しています。Relipa は単なる技術提供者ではなく、あなたのデジタル変革を共に推進する信頼のパートナーです。企業が抱える課題に合わせて、最適な RAG ワークフローと AI 活用戦略をご提案いたします。ユースケースの整理から PoC、実装、運用までワンストップでサポートいたします。




とは?企業向け活用ガイド.webp)
