

ChatGPTのような生成AIソフトウェアについて語る際、Nvidiaを思い浮かべずにはいられません。Nvidiaは、生成AI革命の初期段階における大きな勝者の一つです。しかし、これまでNvidiaは、OpenAIのような企業が複雑な生成AI機能を処理するために必要なチップを提供していることで最もよく知られていました。
本記事では、NvidiaのNVLMはなんでしょうか。NvidiaのNVLM 1.0のできること、技術、ChatGPTのGPT-4oとの比較などを徹底的に解説していきます。
NvidiaのNVLM 1.0とは?
2024年10月初旬に、NvidiaはNVLM 1.0を発表し、AI業界を驚かせました。このNVLM 1.0は、大規模なマルチモーダル言語モデルのファミリーで、ChatGPTのGPT-4oモデルと同等の性能を発揮できます。
NvidiaのNVLM製品が消費者向けに展開される可能性に興奮する前に、同社が異なるアプローチを取っていることを知っておくべきです。NvidiaはChatGPTやClaude、Geminiの直接的なライバルをリリースするのではなく、モデルの重みを公開し、他の人々がNVLMを使用して独自のAIアプリやシステムを開発できるようにしているのです。
Nvidiaは論文を発表し、NVLM 1.0の紹介と共に、モデルのウェイトとトレーニングコードをオープンソース化することを明らかにしました。
NVLM 1.0は、最先端のマルチモーダル大規模言語モデル(LLM)のファミリーであり、視覚と言語のタスクにおいて最先端の成果を達成し、主要なプロプライエタリモデル(例:GPT-4o)やオープンアクセスモデル(例:Llama 3-V 405BおよびInternVL 2)と肩を並べています。驚くべきことに、マルチモーダルトレーニング後、NVLM 1.0はそのLLMバックボーンを超えて、テキストのみのタスクにおいても精度が向上しています。私たちは、このモデルのウェイトとトレーニングコードをコミュニティ向けにMegatron-Coreでオープンソース化します。
720億パラメータを持つ「NVLM-D-72B」は、NvidiaのフラッグシップLLM(大規模言語モデル)です。同社によると、このモデルは「ビジョンと言語のタスクおよびテキストのみのタスクの両方で、主要なモデルと同等のパフォーマンスを達成している」とのことです。
論文には、マルチモーダル入力を含むさまざまなチャット例が示されています。チャット内の人間は、テキストと画像を使ってプロンプトを入力しています。これらの例から、AIが画像内の人物、動物、物体を非常にうまく識別し、それらに関連する回答を提供していることがわかります。

上記の例では、ユーザーがNVLMにミームの説明を求め、そのAIが非常に優れた説明を行っています。Nvidiaは、このAIの能力について次のように説明しています。
私たちのNVLM-D-1.0-72Bは、OCR(光学文字認識)、推論、位置特定、常識、世界知識、コーディング能力を組み合わせることで、さまざまなマルチモーダルタスクにおいて多彩な能力を発揮します。例えば、モデルは例(a)において『抽象 vs. 論文』というミームの背後にあるユーモアを理解することができます。OCRを使用して各画像に付けられたテキストラベルを認識し、『抽象』に付けられた凶暴なリンクス(オオヤマネコ)と『論文』に付けられた飼い猫を対比させることで、なぜそれが面白いのかを推論して理解します。

NVLMは、他のジェネレーティブAI製品、例えばOpenAIのChatGPTでも見られるように、複雑な数学の問題を解くことができます。それに、NVLMは、例(b)に示されている「画像の左、中、右のオブジェクトの違いは何ですか?」のような場所に依存する質問に効果的に答えるために、正確な位置特定を行います。また、NVLMは、例(d)および(e)に示されているように、表や手書きの擬似コードなどの視覚情報に基づいて、数学的な推論やコーディングを行うことができます。
また、Nvidiaによると、NVLM-D-72Bはマルチモーダル訓練後、テキストのみのタスクにおけるパフォーマンスを向上させることができるそうです。
GPT-4oと他の生成AIとの比較
Nvidiaが提供したベンチマークによれば、NVLMはGPT-4o、Claude 3.5 Sonnet、Gemini 1.5 Proに匹敵する、もしくはそれ以上の性能を発揮できることが示されています。Nvidiaの公開されたジェネレーティブAI言語モデルは、特定のタスクにおいて、OpenAI、Anthropic、Googleの専用AI製品を実際に上回ることもあります。さらに、NVLM-D-72BはMetaのオープンアクセスLlama AIプラットフォームと同等の性能を持っていることも、以下の表で示されています。
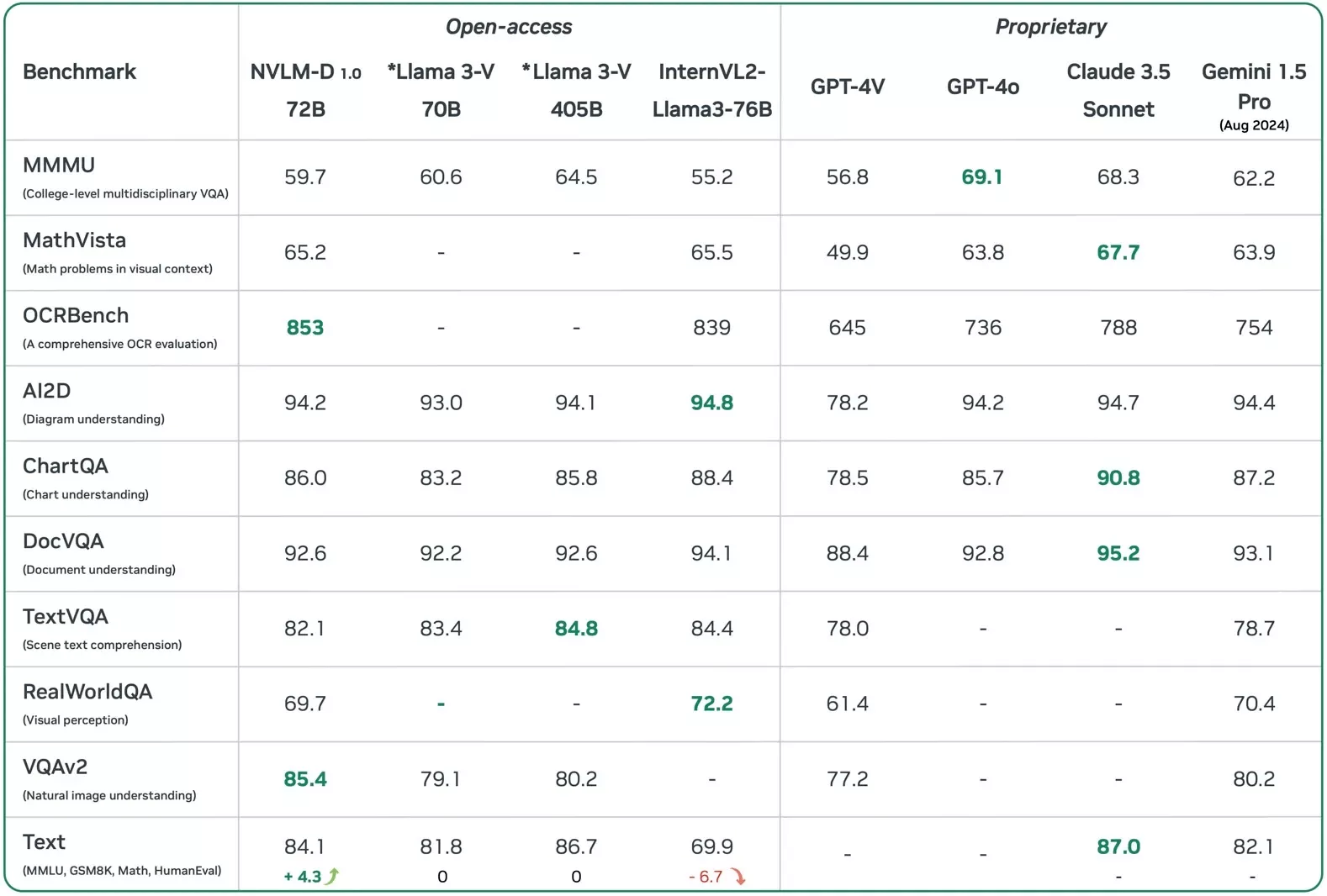
VentureBeat(米国の主要テクノロジー系メディア)が指摘しているように、Nvidiaの驚くべき発表は一部のAI研究者を驚かせました。
上記の表で、NVLM 1.0を主要なプロプライエタリおよびオープンアクセスのマルチモーダルLLM(大規模言語モデル)と比較しています。*Llama 3-Vのモデルウェイトはまだ公開されていないことに注意してください。結果は、NVLM 1.0がビジョンと言語、テキストのみのタスクの両方において、主要なモデルと同等の性能を達成していることを示しています。特に、私たちの72Bモデルは、これまでで最高のOCRBenchとVQAv2のスコアを達成しました。NVLMは、MathVista、OCRBench、ChartQA、DocVQAなどの主要なベンチマークでGPT-4oに匹敵するか、それを上回る性能を示しており、MMMUを除くすべてのベンチマークで優れた結果を残しています。
特に重要なのは、マルチモーダルLLMをテキストのみのタスクにおいてバックボーンLLMと比較した点です。Llama 3-Vの70Bおよび405Bモデルは、マルチモーダルトレーニング中にバックボーンLLMが凍結されているため、テキストのみのタスクで性能低下は見られません。一方、InternVL 2の主要モデルは、MMLU、GSM8K、MATH、HumanEvalなどのテキストのみのベンチマークで大幅な性能低下が見られました。
対照的に、NVLM-1.0 72Bモデルは、テキストのみの数学およびコーディングベンチマークでそのバックボーンLLMを上回る著しい改善を示し、マルチモーダルトレーニング後の平均精度は4.3ポイント向上しました。結果は、Gemini 1.5 Proを上回る性能を発揮したNVLM-1.0 72Bが、数学やコーディング、推論などのテキストのみのタスクにおいても非常に優れたパフォーマンスを示していることを証明しています。
NVLMの性能だけでなく、Nvidiaがこれをオープンソースプロジェクトとして公開するという決断も注目されています。OpenAI、Claude、Googleのような企業がこれをすぐに行うとは期待されていないため、Nvidiaのアプローチは、AI研究者や小規模な企業に利益をもたらす可能性があります。彼らは強力なマルチモーダルLLMにアクセスでき、それに対して費用を払う必要がないからです。
OpenAIはエンドユーザー向けに直接供給することを目的として設計されているため、APIの利用コストはかなり高価です。しかし、それは非常に有用で強力です。しかし、NVLM 1.0のリリースにより、強力な商用製品へと発展するアイデアが大いに促進されるでしょう(これがAIアプリケーションの分野においてゲームチェンジングなイベントになる可能性が非常に高いです)。
NVLM 1.0についての定性的研究
Nvidiaは以下にいくつかの定性的な研究を提供しています。

NVLM-1.0-D 72Bモデルは、優れた指示追従能力を示しています。指示に基づいて、生成するテキストの長さを適切にコントロールします。また、提供された画像に対して非常に高品質で詳細な説明を生成することができます。

NVLM-1.0-D 72Bモデルは、段階的な数学的推論を提供することで数学の問題を解くことができます。可読性を高めるために、数式はLaTeXで表示します。
NVLM-1.0の技術的ハイライト
以下は、私たちの研究における主要な技術的ハイライトです。
・モデル設計について、デコーダーのみを使用するマルチモーダルLLM(例:LLaVA)と、クロスアテンションベースのモデル(例:Flamingo)の包括的な比較を行いました。両方のアプローチの強みと弱みを考慮し、トレーニング効率とマルチモーダル推論能力を強化する新しいアーキテクチャを提案しています。
・さらに、 タイルベースの動的な高解像度画像に対して、1次元タイルタグ付け設計を導入しました。これにより、マルチモーダル推論やOCR関連のタスクでのパフォーマンスが大幅に向上しました。
・トレーニングデータに関して、マルチモーダルの事前トレーニングと教師ありファインチューニングデータセットに関する詳細な情報を精密に選定して提供しています。私たちの調査では、すべてのアーキテクチャにおいて、データセットの質とタスクの多様性がスケールよりも重要であることが示されています。これは事前トレーニングフェーズでも同様です。
・特に注目すべきは、 NVLM-1.0モデル向けに、プロダクション品質のマルチモーダリティを開発し、視覚と言語のタスクに優れるだけでなく、テキスト専用の性能も維持し、さらに改善しています。これを実現するために、高品質なテキスト専用データセットをマルチモーダル学習に統合し、大量のマルチモーダルな数学と推論データを取り入れました。この結果、モダリティをまたぐ数学やコーディングの能力が向上しています。
まとめ
現在、NVLM 1.0は発表されたばかりであり、まだ十分な情報が揃っていません。私たち一般のChatGPTユーザーとしては、Nvidiaの発表がもたらす成果を見守る必要があります。具体的には、NVLMを活用した商業製品が市場に出るのを待つことになります。これが早く実現すれば、OpenAI、Anthropic、Googleなどの企業のビジネス決定に影響を与え、業界全体にとってもプラスになるでしょう。
弊社レリパでは、NVLMに関する最新情報(機能、アクセス方法、特徴など)を常に更新しています。次回の記事をどうぞお楽しみに。
低コストで質の高いオフショア開発会社にお探しなら、弊社の得意な技術スキルを向上しながら、世界の最先端技術にキャッチアップし続けているRelipaにお問い合わせください。





