

ビジネス現場でのAI活用が急速に進む中、「自社特有のナレッジを正確に反映させたAIを作りたい」というニーズが爆発的に増えています。その解決策として、今最も注目されている技術が RAG(検索拡張生成) です。特に、ノーコードプラットフォーム「Dify」を用いたRAG構築は、開発スピードと運用の柔軟性から、多くの AI開発会社 も推奨するスタンダードな手法となりつつあります。
本記事では、AI開発会社の視点から、DifyにおけるRAGの基本概念を分かりやすく解説します。さらに、プロの現場でも実践されている「高精度な社内アプリケーションの構築フロー」や「精度向上のための具体的なノウハウ」まで、初めての方でも迷わず導入できるよう徹底ガイドいたします。
DifyにおけるRAGの概念
Difyとは?
Difyは、大規模言語モデル(LLM)を活用したアプリケーションをノーコードで開発できる、最先端のオープンソース・プラットフォームです。AI開発会社の現場でも、開発スピードと保守性の高さから、プロトタイプ開発や社内ツール構築の標準的な基盤として採用されるケースが増えています。

BaaS(Backend as a Service)とLLMOps(Large Language Model Operations)の機能を統合しており、非エンジニアでも高性能な生成AIアプリを効率的に構築・運用できるよう設計されています。
高度なセキュリティ: AI開発会社が推奨する「オンプレミス(セルフホスト)」運用にも対応。Docker/Kubernetes経由で社内サーバーに構築すれば、情報漏洩リスクを最小限に抑えつつ、企業セキュリティ基準に準拠した運用が容易です。
マルチモデル対応: GPT-4o、Claude 3.5、Gemini 1.5 Proなど、最新のLLMを自在に組み合わせ可能です。
>>>関連記事:
RAGとは?
RAG(Retrieval-Augmented Generation:検索拡張生成)は、従来のデータ検索技術とLLMを高度に組み合わせたAIフレームワークです。
AI開発会社の視点では、LLMの最大の課題である「ハルシネーション(もっともらしい嘘)」を防ぎ、専門的な社内ドキュメントに基づいて回答させるための必須技術と定義しています。
2026年現在は、従来のテキスト検索に加え、ハイブリッド検索(ベクトル検索+キーワード検索)や画像・図表を読み解くマルチモーダルRAGが進化し、リアルタイムでのデータ統合がビジネスにおける標準仕様となっています。
>>>関連記事:
Dify RAGとは?
「Dify RAG」とは、AI開発プラットフォーム Dify が 検索拡張生成RAGに対応することで、より正確性・信頼性の高いAIアプリを効率的に立ち上げられる仕組みのことです。
Dify RAGは、Dify自身とRAGの強みを活かすことで、以下のような最適な特徴を備えています。
- 外部知識への効率的なアクセス: RAGを統合することで、LLMが持たない知識を外部ナレッジベースやデータベースから取得可能となり、ハルシネーション問題を軽減できます。
- 直感的かつ迅速なAIアプリ開発: DifyのBaaSとLLMOps環境を活用することで、複雑なコードなしにRAGを利用したAIアプリを効率的に作れられます。
- 多様なアプリケーションシナリオ: カスタマーサポート、企業ナレッジベース、AI検索エンジンなど、自然言語で複数の知識ソースと対話する知的システムを驚くほど手軽に構築可能です。
- 柔軟なLLM統合: ChatGPT、Claude、Geminiなど複数のモデルを接続でき、業務や顧客ニーズに合わせてAIシステムをカスタマイズできます。
Dify RAGで企業が得る5大メリット
多くのAI開発会社がDifyを推奨する理由は、主に以下の5つのメリットに集約されます。
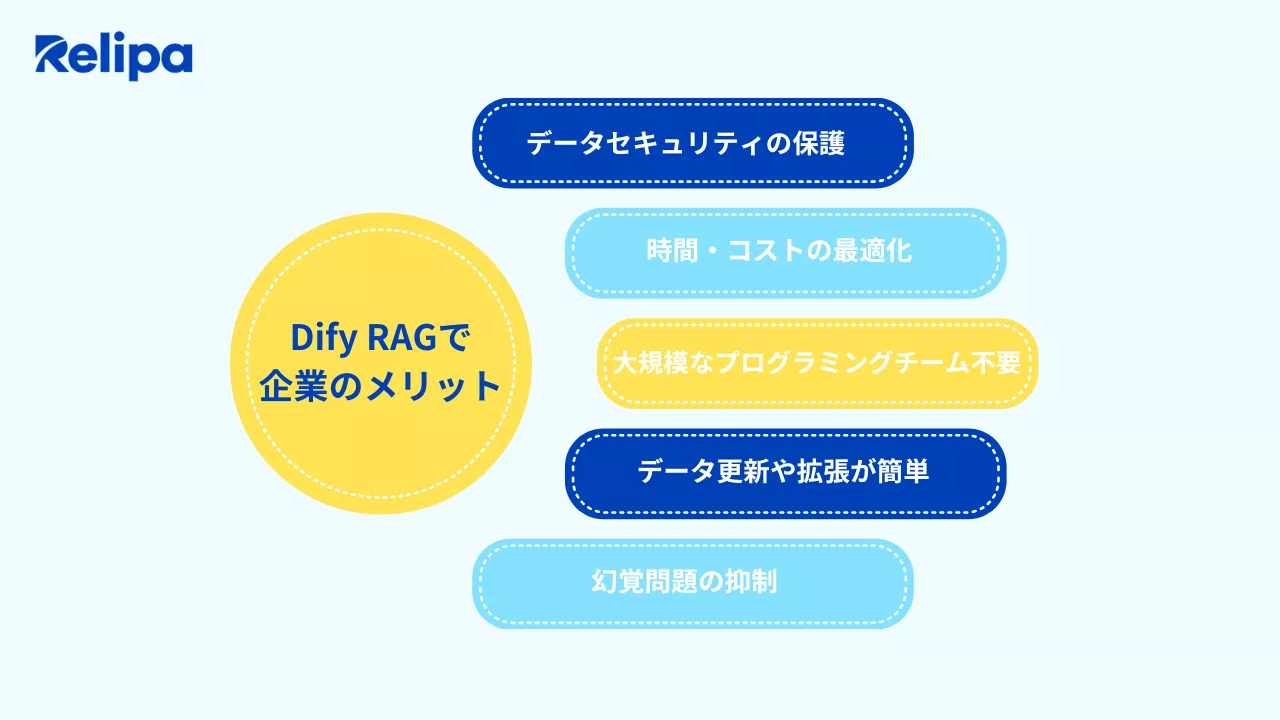
データセキュリティの保護
AI 導入では「文書が外部 LLM に送られるのでは?」という懸念がありますが、Dify は外部に渡すデータを最小限に制御できるため、従来のクラウドAIより安全と評価されています。
文書は Dify 内に留まり、LLM に送るのは検索で抽出された数行だけで、送信ログの確認や外部・閉域・ローカルなど送信先の選択も可能です。
さらに、2025年のv1.1.0でメタデータフィルタリングが追加され、アクセス制御が細かく調整可能になり、情報漏洩リスクをほぼゼロに近づけられます。
時間・コストの最適化
従来は数週間かかっていた FAQ チャットボットの開発も、プログラミング不要で Knowledge Base を作成し、RAG を有効化するだけで、すぐにチャットボットや検索アプリを構築できます。
RAGを利用することで高価なファインチューニングは不要です。また、企業の必要に応じてLLMの種類やリクエスト数を調整でき、運用コストを抑えられます。それどころか、クラウド提供のためインフラ作りが不要のため、初期投資を抑えられます。
大規模なプログラミングチームが不要
専門的なプログラミング知識なしで、エンジニア1名でも RAG を活用した AI アプリを作成することができます。チーム内の AI エンジニアが少なくても、業務担当者が直接 Knowledge Base を更新して運用でき、小規模チームでも即戦力の AI システムを運用可能です。
データ更新や拡張が簡単
Dify では、新しい PDF・Word・Web ページ・Notion などの資料を追加するだけでナレッジベースをすぐに更新できます。Embedding や検索設定の再構築もワンクリックで行えるため、常に最新データを反映した状態で運用が可能です。こうした柔軟性により、会社の成長や新しいサービスの追加にもスムーズに対応でき、無理なく知識基盤を拡張していくことができます。
2025年のプラグインエコシステムで、50以上のツール(Google Search、DALL-Eなど)が追加され、拡張性が飛躍的に向上しました。
幻覚問題の抑制
Dify RAG の大きな強みのひとつは、AIが事実に基づかない回答を生成してしまう「幻覚(Hallucination)」問題を抑制できる点です。
RAG では、AIの生成処理に先立ってナレッジベースから関連情報を検索して提供するため、モデルが自己判断でデータを補完するリスクを大幅に減らせます。さらに、ナレッジベースに企業内の正確な情報を反映させることで、回答の正確性を高め、誤情報の発生を最小化することが可能です。
情報検索→拡張→生成仕組みにより、ユーザーはより信頼性の高いAI回答を得られるだけでなく、業務上の重要な意思決定にも安心して活用できます。
DifyでのRAG実装・ナレッジ設定
RAGのアプリを作るためにはナレッジ設定が必要になってきます。

ナレッジアップロード
PDF、Word、Web ページ、Notion など手元の資料を Dify にアップロードしてナレッジベースを作成します。この時点で、どの資料を優先的に検索対象にするかを考えておくと後の精度向上に役立ちます。
チャンク設定
アップロードした資料を、AI が扱いやすい「意味のまとまり(チャンク)」に分割します。チャンクの分割方式やサイズを適切に設定することで、検索精度や応答の質を高められます。
チャンクサイズが大きすぎると検索で情報を見落とす可能性があり、小さすぎるとコンテキストが分断されるのでバランスが重要です。チャンクサイズは日本語なら400〜600トークンがおすすめです。
また、2025年の更新で、親子チャンク検索(Parent-child Retrieval)が追加され、文脈豊かな応答精度が向上しました。
インデックス方法の選択
インデックス方法とは、アップロードした文書を「検索しやすい形」に加工する仕組みのことです。
文書を解析して検索精度を上げる「高品質」モードと、キーワード中心で軽く作り、コストを抑える「経済的」モードという2つの検索方法が提供されています。2025年のv1.1.0で、メタデータフィルタリングが追加され、インデックス精度が高まりました。
日本語の場合は形態素の複雑さで「経済的」モードは精度が落ちやすいので、重要なナレッジは「高品質」を選びましょう。
埋め込みモデルの選択
文章や質問をベクトルに変換するモデルを指定します。これにより、意味の近い文章同士をベクトル距離で比較できるようになります。モデルの選択によって、検索精度や回答のスピードに差が出るため、用途に合わせて最適なものを選びます。
検索設定
「ベクトル検索」「全文検索」「ハイブリッド検索」など、検索方式を選びます。目的やデータ構造に応じて最適な方法を設定します。ハイブリッド検索は、意味検索とキーワード検索の両方を活用できるため、精度と柔軟性のバランスが良いです。
Dify RAG を利用したアプリ作成
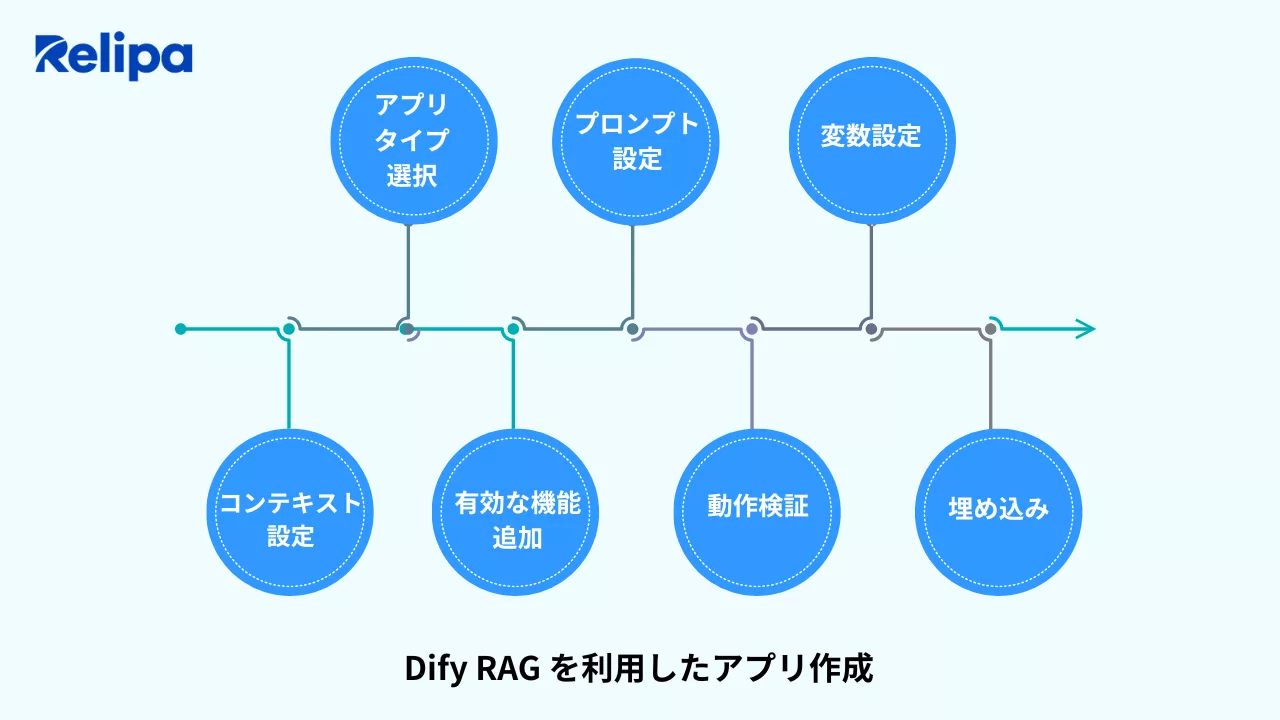
アプリタイプの選択
チャットボット、FAQ システム、質問応答アプリなど目的に応じてアプリの形を選びます。どのタイプにするかでプロンプトや変数の設定も変わるため、最初に明確にしておくと後がスムーズです。
プロンプト設定
AI にどう振る舞ってほしいか、応答時のフォーマット、利用すべきナレッジベースなどをプロンプトで指定します。適切なプロンプトを作ることで、回答の質やハルシネーションの発生を抑えやすくなります。
変数設定
ユーザー入力、メタデータ、会話履歴など必要な変数を設定し、AI に渡す情報を整えます。必要な情報を漏れなく渡すことで、より正確で文脈に沿った回答が得られます。
コンテキスト設定
過去のやりとりや関連ドキュメントなど、AI が応答時に参照すべきコンテキストを指定します。適切なコンテキストを渡すことで、長文や複雑な質問にも正確に回答できるようになります。
有効な機能の追加
必要に応じて、外部 API 呼び出し、ワークフロー連携、ログ保存、アクセス制御などの機能を組み込みます。初期段階では最低限の機能から始め、後で拡張するのが効率的です。
動作検証
実際に質問を投げてテストを行い、検索結果や応答品質を確認します。必要に応じて設定を見直します。このステップでフィードバックを反映させることで、ナレッジベースやチャットボットの精度を段階的に向上させられます。
アプリをウェブサイトに埋め込み
Difyでは、数分でビジネスデータを活用したAIカスタマーサポートやQ&Aアプリを自社サイトに組み込めます。
ウェブサイトへの埋め込みは、主に <iframe> タグ、<script> タグ、またはDifyのChrome拡張機能を使った3つの方法があります。WebAppカードの「埋め込み」ボタンからコードをコピーし、サイトの表示したい場所に貼り付けるだけで簡単に導入可能です。
Dify RAGを活用したチャットボット、ワークフローやその他のアプリケーション構築についてご質問があれば、ぜひRelipaまでお気軽にお問い合わせください。
Dify RAG導入時の注意点
正確で整理されたナレッジを準備すること
Dify RAGを導入する際にまず重要なのは、ナレッジの品質です。登録する情報が誤っていたり古い場合、LLMはそれをそのまま回答に反映してしまうため、結果として信頼性の低い出力が返ってくることになります。そのため、正確で最新の情報を用意することが必要です。
データ形式と構造の整備
PDFやスキャン画像をそのまま登録すると、文字認識の揺れや意味の取り違えが発生する可能性があります。導入前にテキスト化・整形を行い、文書を扱いやすい構造に揃えておくことが重要です。また、文書を粒度の適切な単位に分割し、タイトル・タグなどのメタデータを付けることで検索性能が安定します。
Embeddingモデルと検索設定の適合性
Embedding や検索設定も、単にデフォルトのまま使うのではなく、扱うデータの特徴に合わせた調整が欠かせません。たとえば、FAQ のような短い文書中心のデータと、技術仕様書のように長文が多いデータとでは、検索件数の最適値が異なります。検索結果が広すぎるとノイズを拾い、狭すぎると回答に必要な情報が抜けてしまうため、事前テストが必須です。
運用時の制約の把握
Dify RAGでは、LLMのトークン制限や応答速度、ナレッジ更新の頻度など、運用に関わる制約も存在します。導入前にその特性を把握し、実際の運用フローに影響が出ないよう計画を立てることが求められます。
Dify RAGの精度向上策
精度を高めるには、ナレッジ・検索設定・生成プロンプトの3要素をバランスよく改善することが重要です。
ナレッジの最適化と文書の精緻化
正確な情報の登録に加え、文書の適切なチャンク化(意味のあるまとまりへの分割)とメタデータ付与が検索精度を高めます。不要な情報やノイズを削除し、関連性の高いデータのみをLLMに渡すことで、回答の質が劇的に向上します。
Embeddingと検索ロジックのチューニング
実際のユーザーの質問を分析し、最適なパラメータへ調整し続けることが重要です。
- パラメータ調整: 類似度の閾値変更や検索件数の増減により、情報の取得精度を高めます。
- 高度な検索機能: ハイブリッド検索や再ランキング(Rerank)機能を併用することは、AI開発会社が精度を担保するために推奨する標準的な手法です。
プロンプト設計で生成品質をコントロール
プロンプト設計も精度向上の鍵となります。検索した情報をどのように使うかを明示することで、LLM が回答の構成を誤らなくなります。
例えば、「検索結果の内容のみを根拠に回答してください」「曖昧な場合は『情報不足』と返答してください」と指示するだけで、幻覚を大幅に抑えることができます。また、複雑な手順書や規約を扱う場合には、要約を先に生成させ、その後でユーザーの質問に応答させる二段階プロンプトが効果的です。
運用フィードバックによる継続的な改善
運用後のフィードバックを収集し、検索の挙動や回答品質を定期的に検証することで、Dify RAGは継続的に改善できます。ユーザーからの質問ログを分析し、誤回答が発生した部分を中心にナレッジ更新や設定調整を行うことで、実際の利用シーンに最適化された高精度な運用が可能になります。
今後の展望
Dify RAGは、ナレッジ検索と生成モデルを組み合わせた仕組みとして、今後も着実に実用性が高まると考えられます。
この流れを見据え、現時点でDify RAGを正しく理解し、社内での実証実験や本格導入を進めることは、中長期的な競争優位性を確保する極めて重要な戦略的判断となるでしょう。
まとめ
DifyとRAGの組み合わせは、企業が膨大な情報を効率的に活用し、高精度な回答を生成するための強力なソリューションです。社内データを直接参照しながら回答を生成することで、セキュリティを確保しつつ、AIの課題であるハルシネーション(幻覚)の抑制にも大きく貢献します。
今後も技術の進化とともに、Dify RAGは実用性がさらに高まり、企業の情報活用を革新する存在となるでしょう。この技術を戦略的に導入することで、業務効率と情報活用力の両方を飛躍的に向上させることが可能です。
日本市場において約10年にわたり、ソフトウェア開発、技術コンサルティング、DX、そしてAI分野のサービスを提供してきたAI開発会社として、Relipaは多くの企業の成長を支えてきました。弊社は、最新の技術トレンドに基づいた最適かつ持続可能なソリューションをお届けします。
Relipaのエンジニアチームは、単なる運用にとどまらず、システムアーキテクチャ、データインフラ、AIモデル運用に深い知見を持つプロフェッショナル集団です。
- Dify RAGの導入・構築支援
- 高精度な社内AIアプリのカスタマイズ
- セキュアなデータ基盤の設計
Difyの使い方やRAG技術の活用に関してご不明な点がありましたら、信頼できるAI開発会社であるRelipaまで、どうぞお気軽にお問い合わせください。私たちは、御社のAI活用を次のレベルへと導く最高のパートナーとなります。







